protectedvoidfinishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) { // Initialize conversion service for this context. if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) && beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) { beanFactory.setConversionService( beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)); }
// Register a default embedded value resolver if no BeanFactoryPostProcessor // (such as a PropertySourcesPlaceholderConfigurer bean) registered any before: // at this point, primarily for resolution in annotation attribute values. if (!beanFactory.hasEmbeddedValueResolver()) { beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal)); }
// Initialize LoadTimeWeaverAware beans early to allow for registering their transformers early. String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false); for (String weaverAwareName : weaverAwareNames) { getBean(weaverAwareName); }
// Stop using the temporary ClassLoader for type matching. beanFactory.setTempClassLoader(null);
// Allow for caching all bean definition metadata, not expecting further changes. beanFactory.freezeConfiguration();
@Override publicvoidpreInstantiateSingletons()throws BeansException { if (logger.isTraceEnabled()) { logger.trace("Pre-instantiating singletons in " + this); }
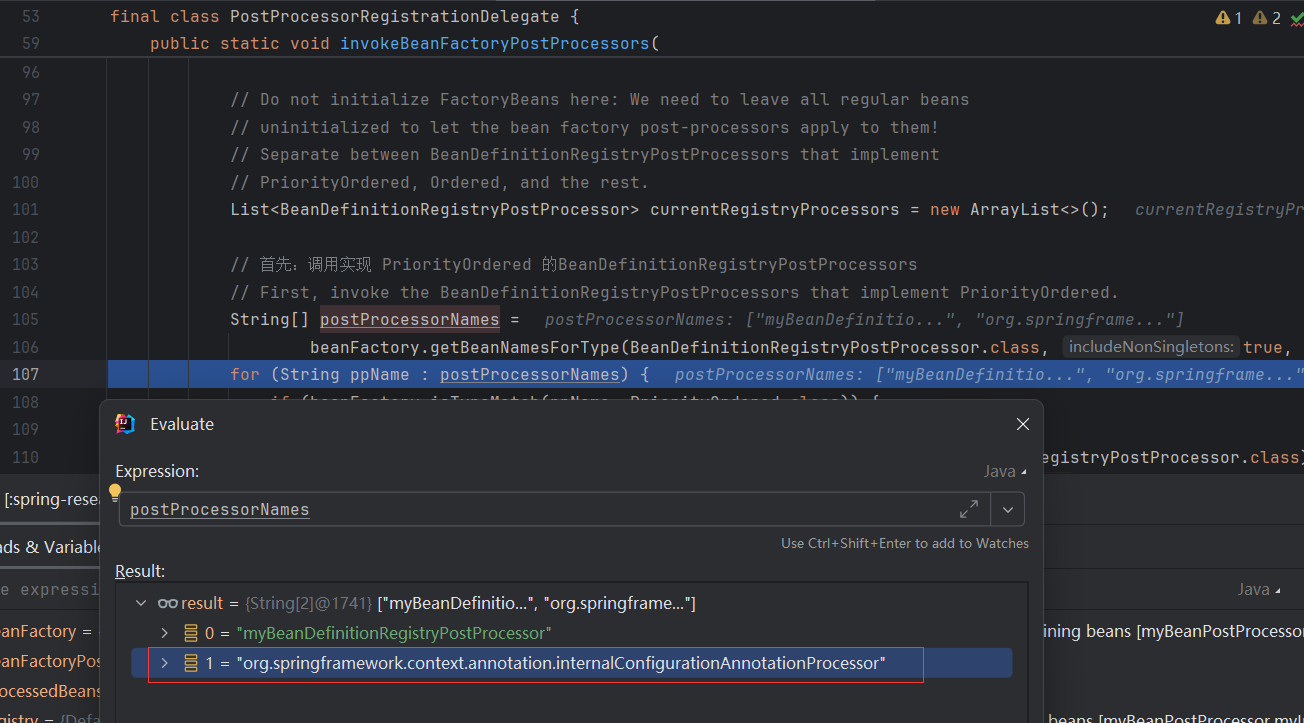
// 存放 BeanNames // Iterate over a copy to allow for init methods which in turn register new bean definitions. // While this may not be part of the regular factory bootstrap, it does otherwise work fine. List<String> beanNames = newArrayList<>(this.beanDefinitionNames);
// 从缓存获取 Bean(注意点:三级缓存) // Eagerly check singleton cache for manually registered singletons. ObjectsharedInstance= getSingleton(beanName); // 如果存在即返回 if (sharedInstance != null && args == null) { if (logger.isTraceEnabled()) { if (isSingletonCurrentlyInCreation(beanName)) { logger.trace("Returning eagerly cached instance of singleton bean '" + beanName + "' that is not fully initialized yet - a consequence of a circular reference"); } else { logger.trace("Returning cached instance of singleton bean '" + beanName + "'"); } } // 针对 FactoryBean 做处理 beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, null); }
else { // prototype 类型的 Bean 不支持循环依赖 // Fail if we're already creating this bean instance: // We're assumably within a circular reference. if (isPrototypeCurrentlyInCreation(beanName)) { thrownewBeanCurrentlyInCreationException(beanName); }
// 检查父工厂中是否已存在该对象 // Check if bean definition exists in this factory. BeanFactoryparentBeanFactory= getParentBeanFactory(); if (parentBeanFactory != null && !containsBeanDefinition(beanName)) { // Not found -> check parent. StringnameToLookup= originalBeanName(name); if (parentBeanFactory instanceof AbstractBeanFactory) { return ((AbstractBeanFactory) parentBeanFactory).doGetBean( nameToLookup, requiredType, args, typeCheckOnly); } elseif (args != null) { // Delegation to parent with explicit args. return (T) parentBeanFactory.getBean(nameToLookup, args); } elseif (requiredType != null) { // No args -> delegate to standard getBean method. return parentBeanFactory.getBean(nameToLookup, requiredType); } else { return (T) parentBeanFactory.getBean(nameToLookup); } }
// 标记 if (!typeCheckOnly) { markBeanAsCreated(beanName); }
// 处理 dependsOn 配置 // Guarantee initialization of beans that the current bean depends on. String[] dependsOn = mbd.getDependsOn(); if (dependsOn != null) { for (String dep : dependsOn) { if (isDependent(beanName, dep)) { thrownewBeanCreationException(mbd.getResourceDescription(), beanName, "Circular depends-on relationship between '" + beanName + "' and '" + dep + "'"); } registerDependentBean(dep, beanName); try { getBean(dep); } catch (NoSuchBeanDefinitionException ex) { thrownewBeanCreationException(mbd.getResourceDescription(), beanName, "'" + beanName + "' depends on missing bean '" + dep + "'", ex); } } }
// 创建 Bean 实例 // Create bean instance. if (mbd.isSingleton()) { // 单例 sharedInstance = getSingleton(beanName, () -> { try { // 创建 Bean return createBean(beanName, mbd, args); } catch (BeansException ex) { // Explicitly remove instance from singleton cache: It might have been put there // eagerly by the creation process, to allow for circular reference resolution. // Also remove any beans that received a temporary reference to the bean. destroySingleton(beanName); throw ex; } }); beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd); }
if (logger.isTraceEnabled()) { logger.trace("Creating instance of bean '" + beanName + "'"); } // 拿到 mbd RootBeanDefinitionmbdToUse= mbd;
// Make sure bean class is actually resolved at this point, and // clone the bean definition in case of a dynamically resolved Class // which cannot be stored in the shared merged bean definition. Class<?> resolvedClass = resolveBeanClass(mbd, beanName); if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) { mbdToUse = newRootBeanDefinition(mbd); mbdToUse.setBeanClass(resolvedClass); }
try { // Give BeanPostProcessors a chance to return a proxy instead of the target bean instance. Objectbean= resolveBeforeInstantiation(beanName, mbdToUse); if (bean != null) { return bean; } } catch (Throwable ex) { thrownewBeanCreationException(mbdToUse.getResourceDescription(), beanName, "BeanPostProcessor before instantiation of bean failed", ex); }
try { // doCreateBean 方法进行创建 Bean ObjectbeanInstance= doCreateBean(beanName, mbdToUse, args); if (logger.isTraceEnabled()) { logger.trace("Finished creating instance of bean '" + beanName + "'"); } return beanInstance; } catch (BeanCreationException | ImplicitlyAppearedSingletonException ex) { // A previously detected exception with proper bean creation context already, // or illegal singleton state to be communicated up to DefaultSingletonBeanRegistry. throw ex; } catch (Throwable ex) { thrownewBeanCreationException( mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", ex); } }
// Allow post-processors to modify the merged bean definition. synchronized (mbd.postProcessingLock) { if (!mbd.postProcessed) { try { applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName); } catch (Throwable ex) { thrownewBeanCreationException(mbd.getResourceDescription(), beanName, "Post-processing of merged bean definition failed", ex); } mbd.postProcessed = true; } }
// Eagerly cache singletons to be able to resolve circular references // even when triggered by lifecycle interfaces like BeanFactoryAware. booleanearlySingletonExposure= (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName)); if (earlySingletonExposure) { if (logger.isTraceEnabled()) { logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references"); } addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); }
if (earlySingletonExposure) { ObjectearlySingletonReference= getSingleton(beanName, false); if (earlySingletonReference != null) { if (exposedObject == bean) { exposedObject = earlySingletonReference; } elseif (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) { String[] dependentBeans = getDependentBeans(beanName); Set<String> actualDependentBeans = newLinkedHashSet<>(dependentBeans.length); for (String dependentBean : dependentBeans) { if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean); } } if (!actualDependentBeans.isEmpty()) { thrownewBeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been " + "wrapped. This means that said other beans do not use the final version of the " + "bean. This is often the result of over-eager type matching - consider using " + "'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example."); } } } }
// 检查属性是否需要运行时引用另外一个 Bean // We must check each value to see whether it requires a runtime reference // to another bean to be resolved. if (value instanceof RuntimeBeanReference) { RuntimeBeanReferenceref= (RuntimeBeanReference) value; return resolveReference(argName, ref); }
// Destroy already created singletons to avoid dangling resources. destroyBeans();
// Reset 'active' flag. cancelRefresh(ex);
// Propagate exception to caller. throw ex; }
finally { // Reset common introspection caches in Spring's core, since we // might not ever need metadata for singleton beans anymore... resetCommonCaches(); contextRefresh.end(); } } }
@Override protectedvoidloadBeanDefinitions(DefaultListableBeanFactory beanFactory)throws BeansException, IOException { // 给指定的 BeanFactory 创建一个 XmlBeanDefinitionReader 进行读取和解析 XML // Create a new XmlBeanDefinitionReader for the given BeanFactory. XmlBeanDefinitionReaderbeanDefinitionReader=newXmlBeanDefinitionReader(beanFactory);
// 给 XmlBeanDefinitionReader 设置上下文信息 // Configure the bean definition reader with this context's // resource loading environment. beanDefinitionReader.setEnvironment(getEnvironment()); beanDefinitionReader.setResourceLoader(this); beanDefinitionReader.setEntityResolver(newResourceEntityResolver(this));
// 提供给子类上西安的模板方法:自定义初始化策略 // Allow a subclass to provide custom initialization of the reader, // then proceed with actually loading the bean definitions. initBeanDefinitionReader(beanDefinitionReader); // 真正的去加载 BeanDefinitions loadBeanDefinitions(beanDefinitionReader); }
publicintloadBeanDefinitions(EncodedResource encodedResource)throws BeanDefinitionStoreException { Assert.notNull(encodedResource, "EncodedResource must not be null"); if (logger.isTraceEnabled()) { logger.trace("Loading XML bean definitions from " + encodedResource); }
protectedvoiddoRegisterBeanDefinitions(Element root) { // Any nested <beans> elements will cause recursion in this method. In // order to propagate and preserve <beans> default-* attributes correctly, // keep track of the current (parent) delegate, which may be null. Create // the new (child) delegate with a reference to the parent for fallback purposes, // then ultimately reset this.delegate back to its original (parent) reference. // this behavior emulates a stack of delegates without actually necessitating one. BeanDefinitionParserDelegateparent=this.delegate; this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) { StringprofileSpec= root.getAttribute(PROFILE_ATTRIBUTE); if (StringUtils.hasText(profileSpec)) { String[] specifiedProfiles = StringUtils.tokenizeToStringArray( profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS); // We cannot use Profiles.of(...) since profile expressions are not supported // in XML config. See SPR-12458 for details. if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) { if (logger.isDebugEnabled()) { logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec + "] not matching: " + getReaderContext().getResource()); } return; } } }
preProcessXml(root); // 真正解析 XML parseBeanDefinitions(root, this.delegate); postProcessXml(root);
可选项:此外由于 Spring 源码工程配置了 checkStyle,在做测试类的时候有些方法不能够满足 Spring 的规范要求(由于使用 Intellij IDEA 自动生成或者格式化的代码不满足要求,比如 tab indent,实体类 this 指向,包括 import 隔行等规则),可以通过在 src/checkstyle/checkstyle.xml 中添加过滤规则:
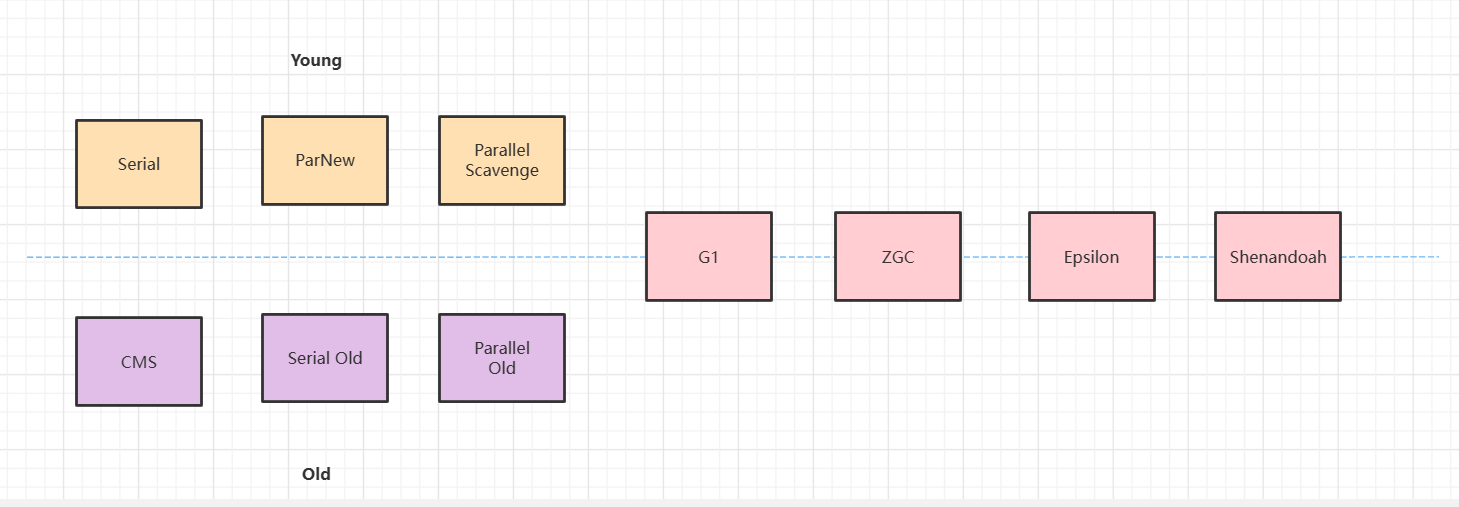
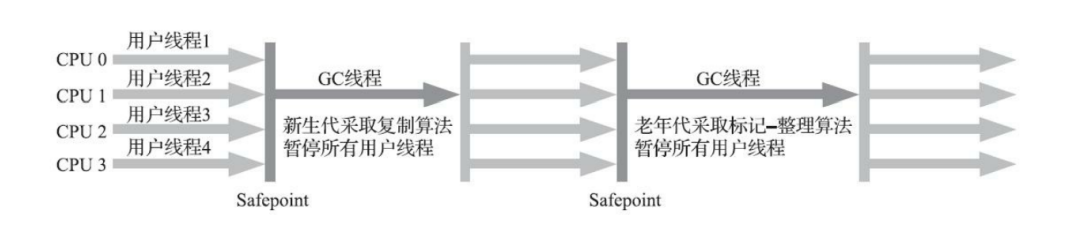
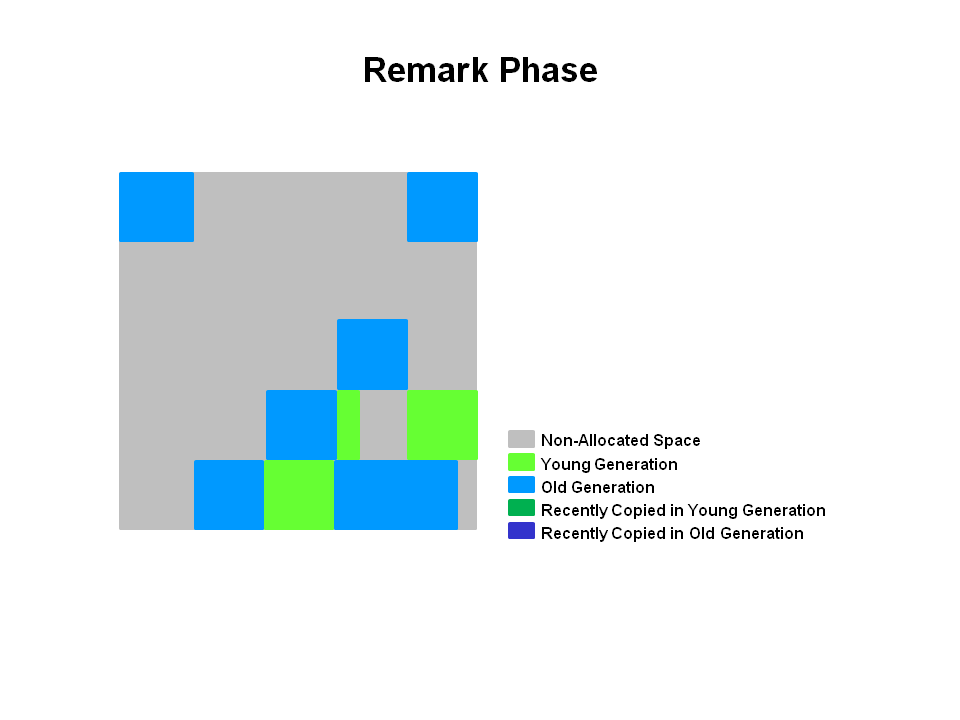
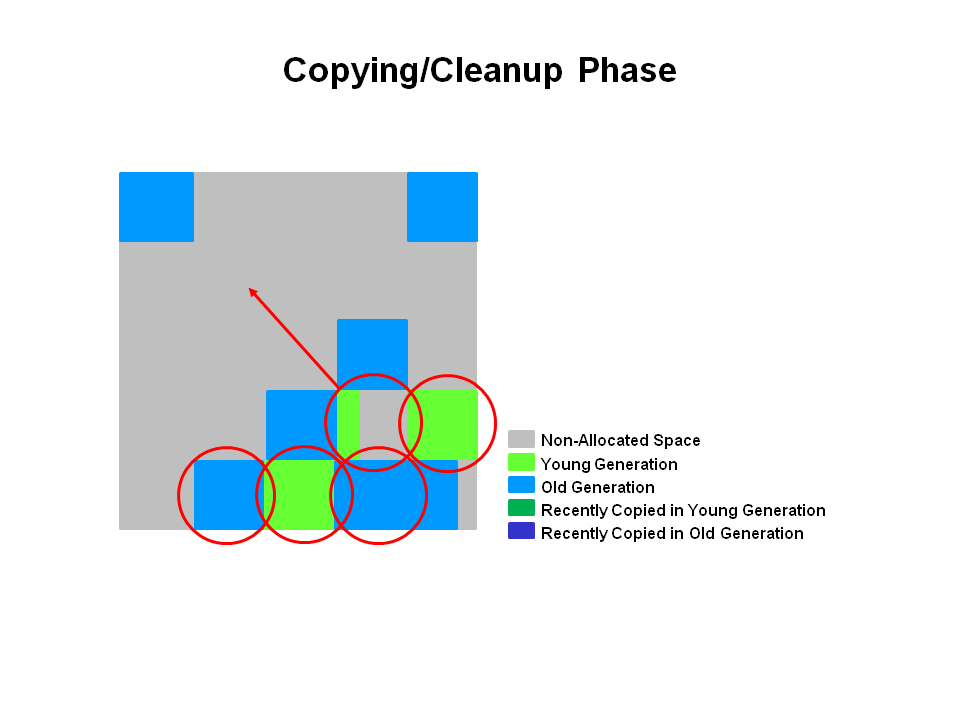
另外:Parallel Scavenge 收集器架构中本身有 PS MarkSweep 收集器来进行老年代收集,并非直接调用 Serial Old 收集器,但 PS MarkSweep 收集器与 Serial Old 的实现几乎是一样的,所以在官方的许多资料中都是直接以 Serial Old 代替 PS MarkSweep 进行讲解。
(图源自《深入理解Java虚拟机(第2版)》)
2.7 Parallel Old 收集器
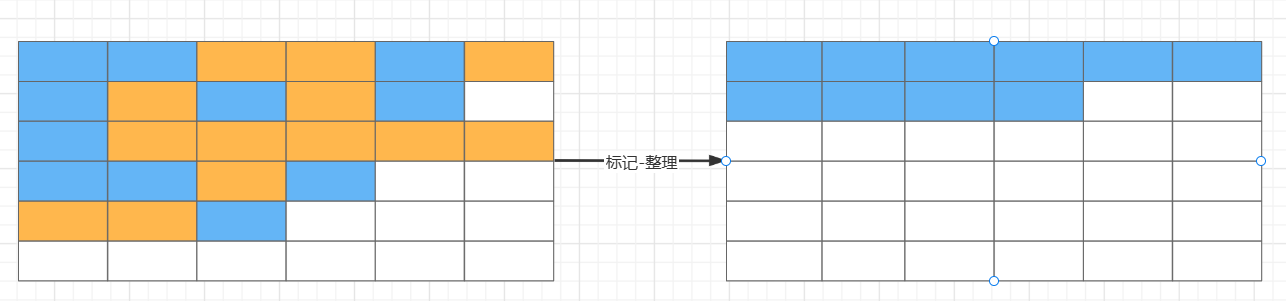
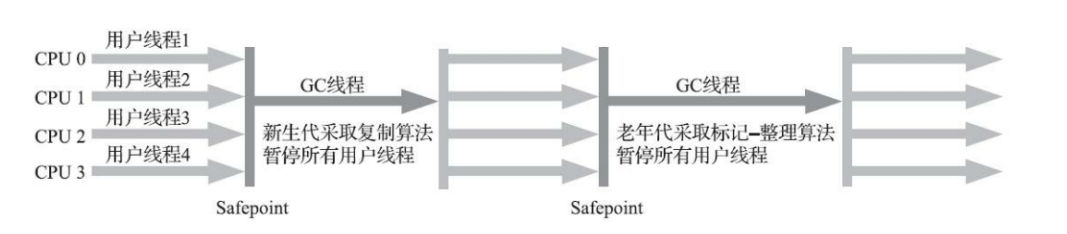
Parallel Old 是 Parallel Scavenge 收集器的老年代版本,支持多线程并发收集,基于标记-整理算法实现。
JDK1.6 及之后用来代替老年代的 Serial Old 收集器;(在此之前,如果新生代选择了 Parallel Scavenge 收集器,老年代除了 Serial Old(PS MarkSweep) 收集器以外别无选择,其他表现良好的老年代收集器,如 CMS 无法与它配合工作。)
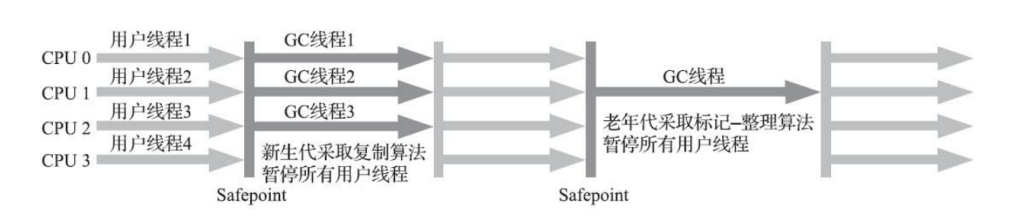
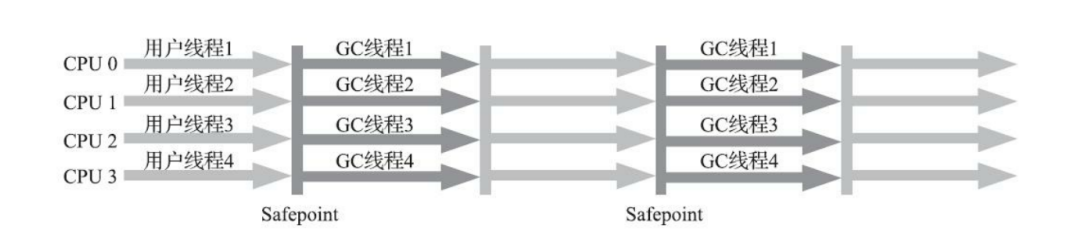
在Server模式,多CPU的情况下;在注重吞吐量以及CPU资源敏感的场景,就有了 Parallel Scavenge 加 Parallel Old 收集器的应用组合;
使用方式:-XX:+UseParallelOldGC
(图源自《深入理解Java虚拟机(第2版)》)
2.8 CMS 收集器
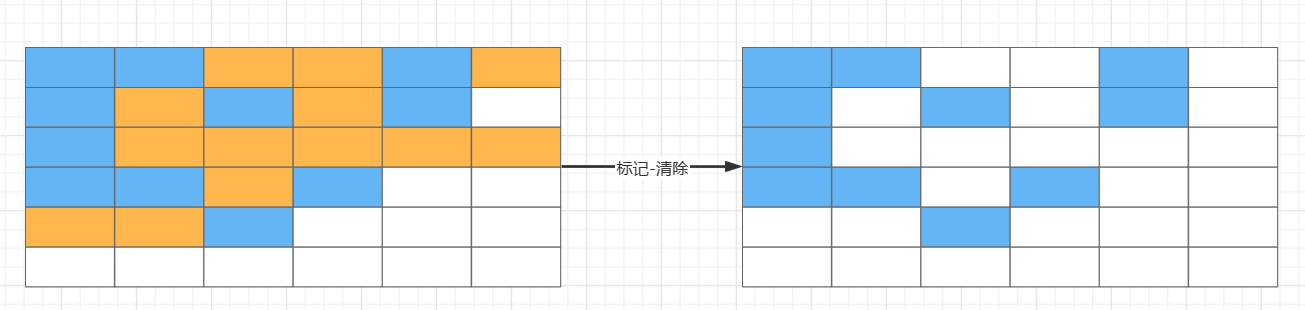
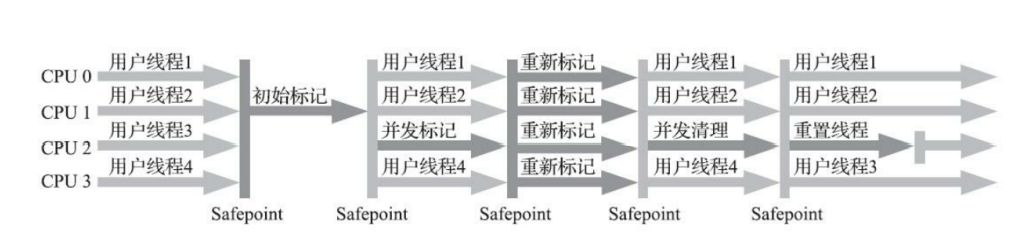
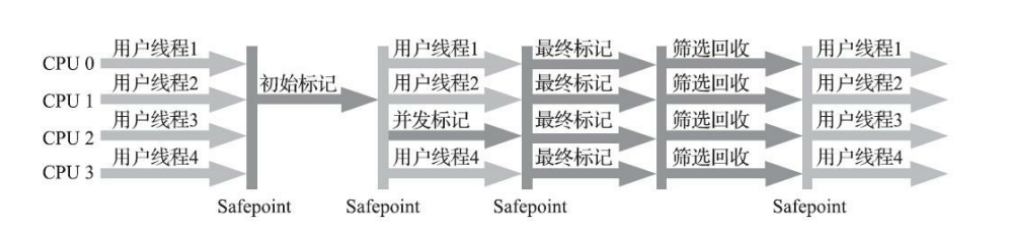
CMS(concurrent mark sweep)是以获取最短垃圾收集停顿时间为目标的收集器,CMS 收集器的关注点尽可能缩短垃圾收集时用户线程的停顿时间,停顿时间越短就越适合与用户交互的程序验,CMS 收集器使用的算法是标记-清除算法实现的;
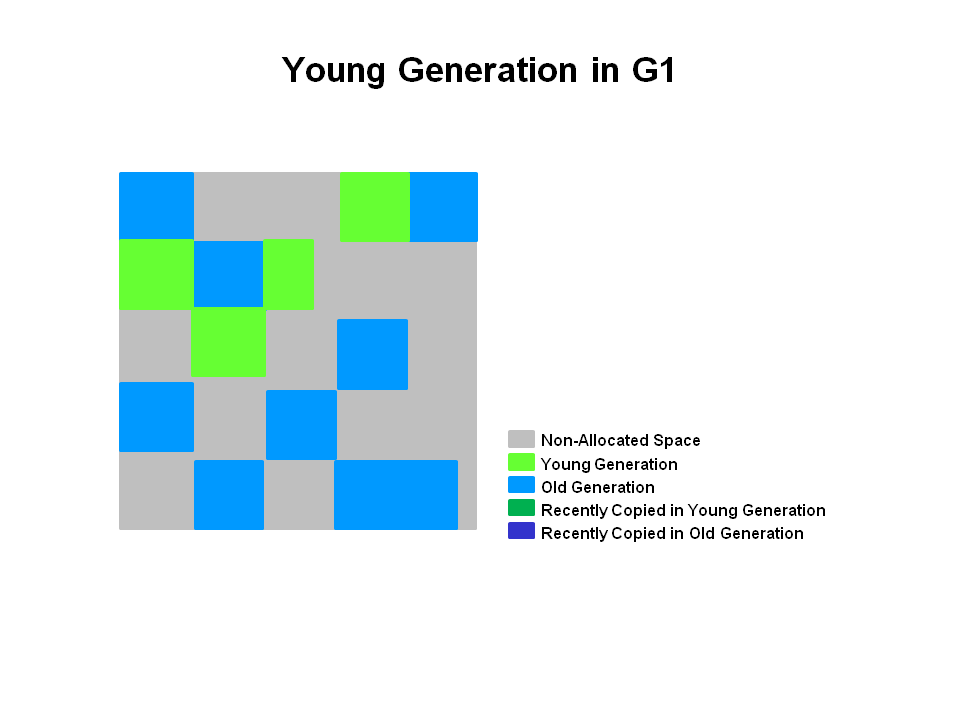
G1 不再坚持固定大小以及固定数量的分代区域划分,而是把连续的 Java 堆划分为多个独立区域(Region),每一个 Region 都可以根据需要扮演新生代的 Eden 空间、 Survivor 空间、老年代空间。
① 使用G1收集器时,它将整个 Java 堆划分成约2048个大小相同的独立 Region 块,每个 Region 块大小根据堆空间的实际大小而定,为2的N次幂,即1MB,2MB,4MB,8MB,16MB,32MB。 ② 虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分Region (不需要连续)的集合。通过Region的动态分配方式实现逻辑上的连续。 ③ G1垃圾收集器还增加了一种新的内存区域,叫做 Humongous 内存区域。主要用于存储大对象,如果超过 1.5 个 Region,就放到 H 区。一般被视为老年代。
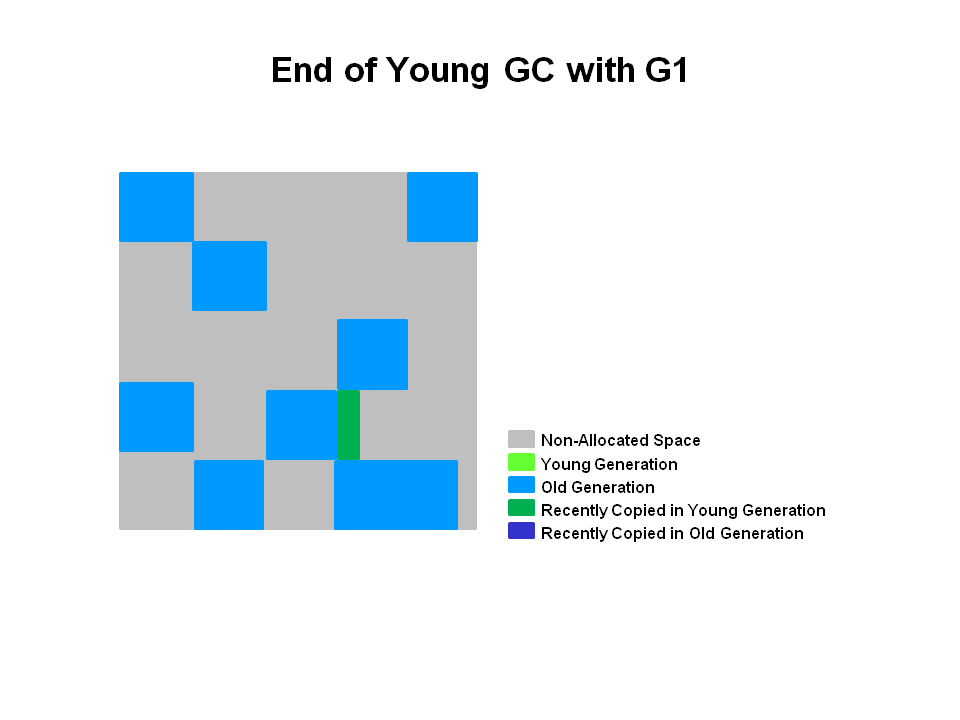
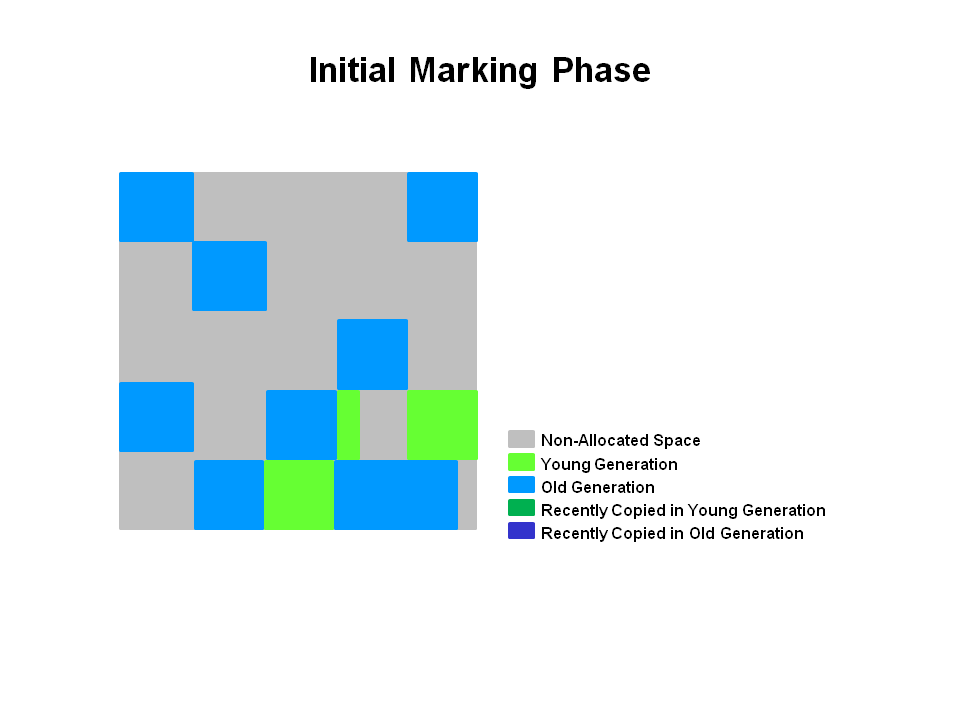
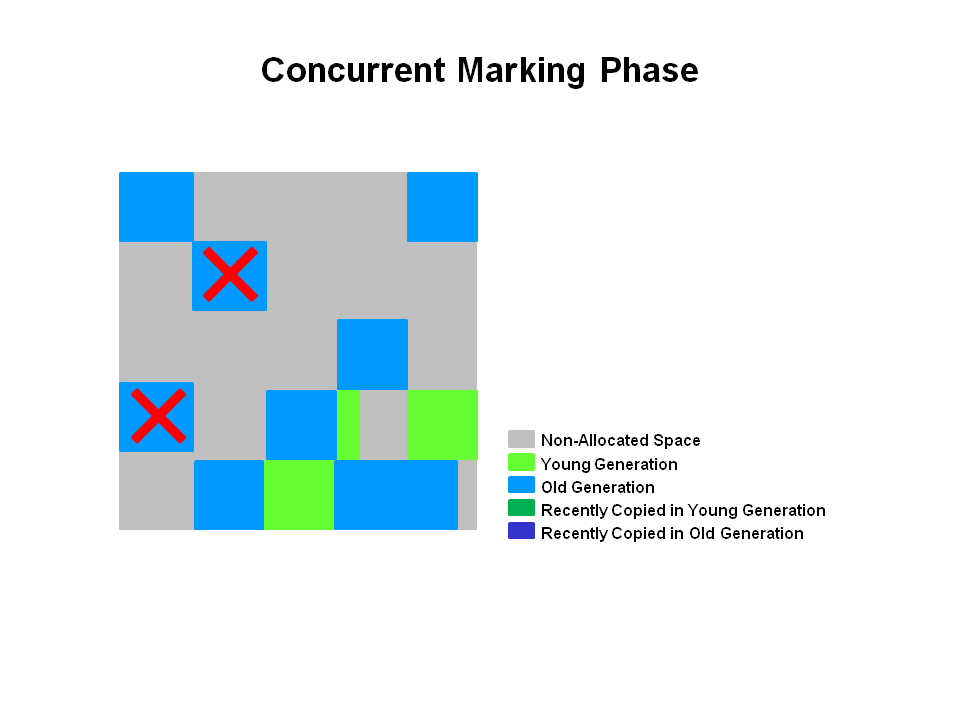
G1 GC过程 G1 提供了两种 GC 模式,Young GC 和 Mixed GC,两种均是完全 Stop The World 的。
Young GC:选定所有年轻代里的 Region,通过控制年轻代的 Region 个数,即年轻代内存大小,来控制 Young GC 的时间开销。
Mixed GC:选定所有年轻代里的 Region,外加根据 global concurrent marking 统计得出收集收益高的若干老年代 Region。在用户指定的开销目标范围内尽可能选择收益高的老年代 Region。
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded // 1. 首先,检查一下指定名称的类是否已经加载过,如果加载过了,就不需要再加载,直接返回。 Class<?> c = findLoadedClass(name); if (c == null) { longt0= System.nanoTime(); try { if (parent != null) { // 2. 判断一下是否有父加载器,若有交给父加载器加,否则调用 BootstrapClassLoader 加载。 c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader }
if (c == null) { // 3. 如果第二步骤依然没有找到指定的类,那么调用当前类加载器的 findClass 方法来完成类加载。 // If still not found, then invoke findClass in order // to find the class. longt1= System.nanoTime(); c = findClass(name);
// this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } }
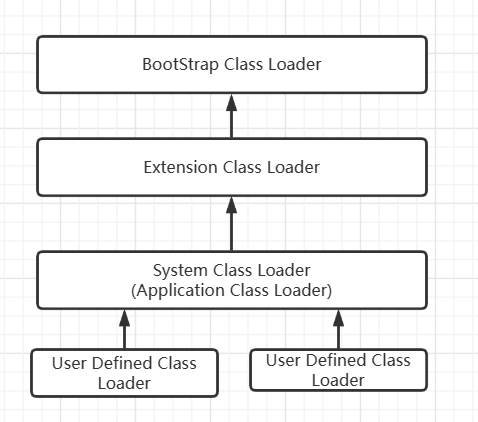
/** * This class is used by the system to launch the main application. Launcher类 */ publicclassLauncher { privatestaticURLStreamHandlerFactoryfactory=newFactory(); privatestaticLauncherlauncher=newLauncher(); // 1. Luncher 类加载后会从此静态变量调用到默认的构造方法 privatestaticStringbootClassPath= System.getProperty("sun.boot.class.path");
publicLauncher() { // Create the extension class loader ClassLoader extcl; try { extcl = ExtClassLoader.getExtClassLoader(); // 2. 扩展类加载器 } catch (IOException e) { thrownewInternalError( "Could not create extension class loader", e); }
// Now create the class loader to use to launch the application try { loader = AppClassLoader.getAppClassLoader(extcl); // 3. 应用类加载器(系统类加载器) } catch (IOException e) { thrownewInternalError( "Could not create application class loader", e); }
// Also set the context class loader for the primordial thread. // 4. 设置 ContextClassLoader 为应用类加载器(系统类加载器) Thread.currentThread().setContextClassLoader(loader);
// Finally, install a security manager if requested Strings= System.getProperty("java.security.manager"); if (s != null) { // init FileSystem machinery before SecurityManager installation sun.nio.fs.DefaultFileSystemProvider.create();
/* * The class loader used for loading installed extensions. 关于 ExtClassLoader */ staticclassExtClassLoaderextendsURLClassLoader {
// ...
privatestatic ExtClassLoader createExtClassLoader()throws IOException { try { // Prior implementations of this doPrivileged() block supplied // aa synthesized ACC via a call to the private method // ExtClassLoader.getContext().
/** * The class loader used for loading from java.class.path. 关于 AppClassLoader * runs in a restricted security context. */ staticclassAppClassLoaderextendsURLClassLoader {
// Note: on bugid 4256530 // Prior implementations of this doPrivileged() block supplied // a rather restrictive ACC via a call to the private method // AppClassLoader.getContext(). This proved overly restrictive // when loading classes. Specifically it prevent // accessClassInPackage.sun.* grants from being honored. // return AccessController.doPrivileged( newPrivilegedAction<AppClassLoader>() { public AppClassLoader run() { URL[] urls = (s == null) ? newURL[0] : pathToURLs(path); returnnewAppClassLoader(urls, extcl); } }); }
final URLClassPath ucp;
/* * Creates a new AppClassLoader */ AppClassLoader(URL[] urls, ClassLoader parent) { super(urls, parent, factory); ucp = SharedSecrets.getJavaNetAccess().getURLClassPath(this); ucp.initLookupCache(this); }
/** * Override loadClass so we can checkPackageAccess. // 0. 重写 loadClass 方法:checkPackageAccess 之后调用 super.loadClass */ public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { inti= name.lastIndexOf('.'); if (i != -1) { SecurityManagersm= System.getSecurityManager(); if (sm != null) { sm.checkPackageAccess(name.substring(0, i)); } }
if (ucp.knownToNotExist(name)) { // The class of the given name is not found in the parent // class loader as well as its local URLClassPath. // Check if this class has already been defined dynamically; // if so, return the loaded class; otherwise, skip the parent // delegation and findClass. Class<?> c = findLoadedClass(name); if (c != null) { if (resolve) { resolveClass(c); } return c; } thrownewClassNotFoundException(name); }
return (super.loadClass(name, resolve)); }
// ... } }
5 自定义类加载器
自定义类加载器的目的:
隔离加载类:模块隔离,把类加载到不同的应用选中。比如 Tomcat 这类 Web 应用服务器,内部自定义了好几中类加载器,用于隔离 Web 应用服务器上的不同应用程序。